

|
John McDonoughVisiting Scientist Language Technologies Institute School of Computer Science Carnegie Mellon University 5000 Forbes Avenue, Pittsburgh, PA-15213 Office: 5411 Gates Hillman Complex Phone: 412 952 2881 e-mail:johnmcd at cs dot cmu dot edu Affiliations:Language Technologies Institute Machine Learning for Signal Processing Group |

|
Reaserch Interests
My research concerns automatic speech recognition (ASR) in general and distant speech recognition (DSR) in particular. I think of the latter as being any situation where a microphone is not located in the immediate vicinity of the mouth. This implies that in addition to contending with all of the usual problems associated with ASR, there are also problems stemming noise, room reverberation, speech of other speakers, etc. Such effects make DSR a far more difficult problem than conventional ASR, and moreover, a problem that is by no means solved. Using a microphone array to capture the far-field speech and then applying acoustic array processing is an extremely effective way to reduce the total system error rate. When the signals from each channel in a microphone array are appropriately combined, the array is able to act as a spatial filter, emphasizing signals emanating from a desired direction and suppressing others. This selective spatial sensitivity is summarized in a beampattern, which is a plot---usually in decibels---of the sensitivity of the array as a function of angle of incidence---usually represented as a direction cosine. Here is the beampattern of a minimum variance distortionless response (MVDR) beamformer in the presence of a source of coherent interference.
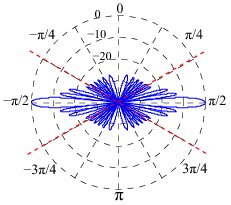
As is apparent from the plot, the beamformer maintains unity gain (0 dB) in the look direction (i.e., direction of the desired source), which is straight ahead in this case, while placing a deep null in the direction of the coherent interference.
Human speech---whether considered in the time or the frequency domain---has very non-Gaussian statistical characteristics; while Gaussian random variables are characterized by frequent but small deviations from their means, super-Gaussian random variables like speech are characterized by large but infrequent deviations from their means. These super-Gaussian characteristics approach the Gaussian, however, whenever clean speech is corrupted either with noise, reverberation or the speech of another speaker; this follows directly from the central limit theorem. Kurtosis and negentropy are statistical measures of deviation from Gaussianity.
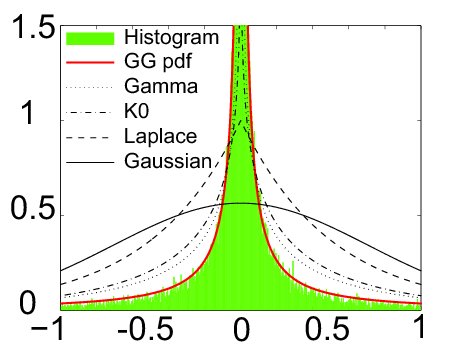
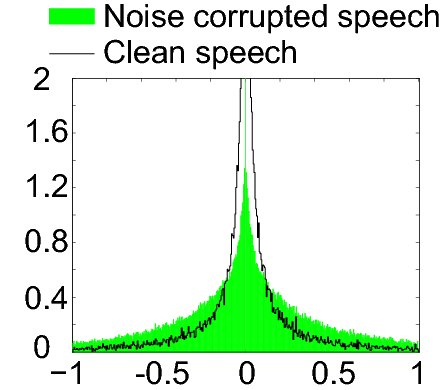
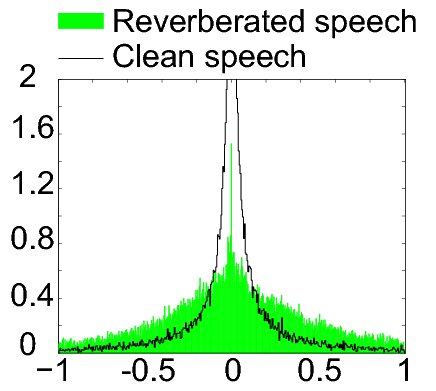
By designing beamforming algorithms that restore the statistical characteristics of the original clean speech, the detrimental effects of noise and reverberation can be removed. This is the principle of operation of the maximum negentropy and maximum kurtosis beamformers, both of which were originally proposed by my students and me.
Here is a table of word error rate results for a simple DSR task where a young child, aged 4--6, repeats a simple phrase spoken by an adult experimenter. The best beamforming result is obtained with our maximum kurtosis beamforming algorithm. Click on the loud speaker to hear the audio; for the audio samples the beamformer is pointed at the child, so her voice is much clearer than that of the adult experimenter. In generating the DSR results, the beamformer was pointed either at the experimenter or child, depending on which was desired.
| %Word Error Rate | |||
|---|---|---|---|
| Beamforming Algorithm | Experimenter | Children | Audio |
| One Channel of Array | 3.4 | 14.2 |

|
| Delay-and-Sum | 2.2 | 7.6 |
|
| Superdirective | 2.1 | 6.5 |
|
| Maximum Kurtosis | 0.6 | 5.3 |
|
| Close-Talking Microphone | 1.9 | 4.2 |
|
An interesting new field of research is the application of spherical microphone arrays to soundfield analysis. Here is a 32-channel spherical array made by mh acoustic.

Spherical arrays have several attractive properties compared to conventional microphone arrays, including an invariance to the direction in which the beam is pointed. Typically, the complete sound field is decomposed into a set of spherical harmonics. The first four radially symmetric spherical harmonics look like this.
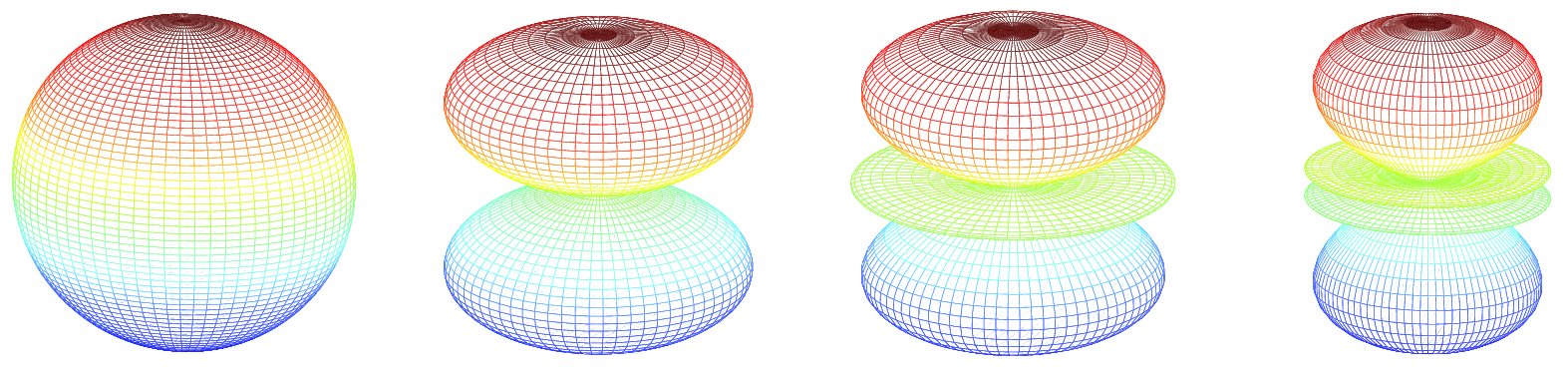
My colleagues and I are currently comparing the effectiveness of conventional versus spherical microphone arrays. At the moment, the latter are still relatively expensive; hence we would like to know if this expense is justified in terms of DSR performance. I'll post our initial results as soon as we have them.
Bio-Sketch
I have been involved in automatic speech recognition (ASR) research since January of 1993, when I joined the speech department at BBN in Cambridge, MA. At BBN I worked for Herb Gish on the Wordspotting and later the Switchboard Projects, both of which were sponsored by the National Security Agency. I was an important contributor to the development of the systems that posted the lowest overall word error rates on the 1995 and 1996 Switchboard evaluations. In the Fall of 1997, I entered graduate school at the Johns Hopkins University (JHU) Center for Language and Speech Processing (CLSP); my advisor was Prof. Fred Jelinek. In May of 2000, I was awarded a Ph.D. for my work in speaker adaptation.From January 2000 until December 2006, I worked at the University of Karlsruhe (UKA) in Karlsruhe, Germany as a researcher and lecturer. While at UKA, I became fluent in German solely by reading Harry Potter novels in translation and was eventually able to hold the lecture Man-Machine Speech Communication entirely in the language. I also developed and taught the lecture Microphone Arrays: Gateway to Hands-Free Speech Recognition. At Karlsruhe, I supervised research in all speech and audio technologies for the EU project CHIL, Computers in the Human Interaction Loop; this included audio-visual speaker tracking, beamforming, hidden Markov Model (HMM) parameter estimation, and speech recognition. I led UKA's participation in the audio segments of the CHIL technology evaluations, which in latter years included coordinating the evaluation task definitions with the US National Institute of Standards and Technology (NIST) as well as top academic and industrial ASR research sites.
In February 2007 I began work at Saarland University (SU) in Saarbruecken, Germany, where I continued to conduct research and lecture about topics related to speech recognition. While at SU, I developed and taught the new course offerings Distant Speech Recognition and Weighted Finite-State Transducers in Speech and Natural Language Processing. At SU, I was principal author for the successful EU project proposal SCALE, Speech Communication with Adaptive Learning, which eventually supported 12 Ph.D. candidates and two postdocs at six academic sites throughout Europe. My team posted the best results in the PASCAL Speech Separation Challenge II. Along with a colleague from UKA, I also completed a book entitled Distant Speech Recognition, which was published by Wiley in April 2009. In the course of my career, I have implemented nearly all of the algorithms described in the latter work, including algorithms for speaker adaptation, speaker tracking, HMM training, manipulation and optimization of weighted finite-state transducers (WFSTs), Bayesian filtering, beamforming, and ASR word hypothesis search.
Beginning in February 2010, I spent a year at Disney Research, Pittsburgh (DRP) founding a research effort in distant speech recognition. In March 2010, I and one of my graduate students from SU held a tutorial on distant speech recognition at ICASSP. I have also served as an invited speaker at several international conferences. Since January of 2011, I have been a visiting scientist at the Language Technologies Institute (LTI) at Carnegie Mellon University, where I continue to conduct research in distant speech recognition while collaborating with colleagues both at the LTI and at DRP. I served as publications chair of the 2011 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics.
Publications (by topic)
- Books and Tutorials
Links and Slides
These publications describe recent work on the general topic of distant speech recognition. They include a book I co-authored with Matthias Woelfel as well a book chapter that I am currently preparing with Kenichi Kumatani, both published by Wiley. There are also the slides from a tutorial I held together with Matthias Woelfel and Friedrich Faubel at ICASSP 2010, as well as other tutorials from the first SCALE winter school. - Distant Speech Recognition
Papers
These papers describe my work together with colleagues in distant speech recognition. - Acoustic Array Processing
Papers
These papers describe our work in acoustic array processing; particularly represented is the rather prodigious body of work that we have produced using non-Gaussian assumptions and techniques based thereon for beamforming prior to distant speech recognition. - Weighted Finite-State Transducers
Papers
These papers describe the work of my colleagues and me in applying the formalism of weighted finite-state transducers to speech recognition. - Speaker Adaptation
Papers
The papers work dating back to my doctoral thesis and earlier in speaker adaptation for automatic speech recognition. - Discriminative HMM Training
Papers
These papers describe my work on discriminative HMM training, and the combination thereof with speaker adaptation techniques. - Robust Feature Extraction
Papers
These papers describe the work I published with my former students on robust feature extraction. - Person and Speaker Tracking Papers
These publications describe my work on person and speaker tracking, which is a necessary first step prior to acoustic beamforming.
Web Sites
- Home
- Distant Speech Recognition (book)
- Distant Speech Recognition (course)
- Weighted Finite-State Transducers in Speech and Natural Language Processing (course)
